【pandas, SQL】ファイル読み込み履歴テーブルを参照して処理対象ファイルを決定するというロジック
はじめに
仕事でPentaho ETLをPython ETLに置き換えるということを行なっている。
File to DBの処理で、処理対象ファイルを決定するというロジックがあった。
chatGPTに相談してサンプルコードを提示してもらったので、その処理内容について解説していく。
開発環境
筆者の開発環境は以下の通り。
| OS | macOS Sonoma 14.4.1 |
| エディタ | Visual Studio Code 1.95.3 (Universal) |
| 仮想環境 | venv |
| 言語 | Python 3.12.2 |
| DB | SQLite 3.43.2 |
| ライブラリ | pandas 2.2.3 |
ディレクトリ構造
ディレクトリ構造はこちら。
Python/
├── .venv/
├── input/
│ ├── AAA.csv
│ ├── CCC.csv
├── pandas/
│ ├── read_sql.py
└── file_history.dbread_sql.pyにメイン処理を書いている。
IN-OUT
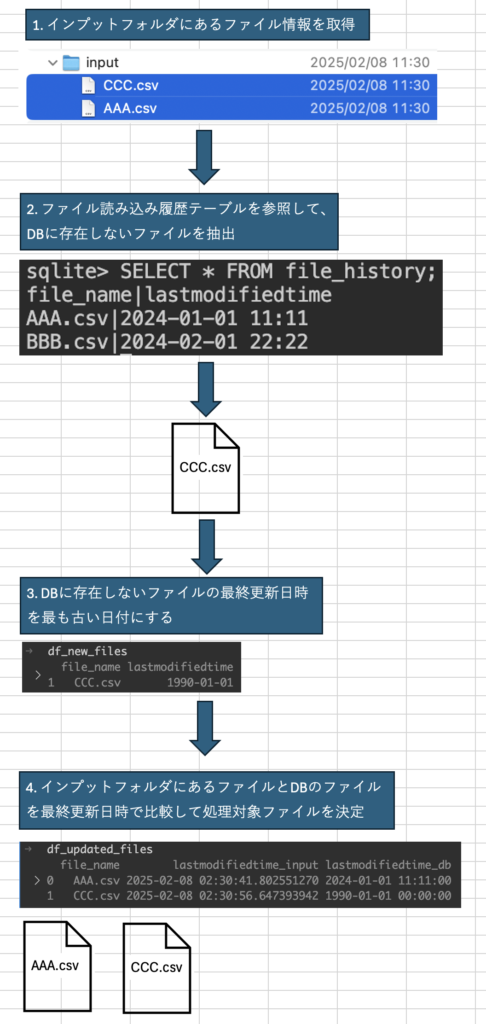
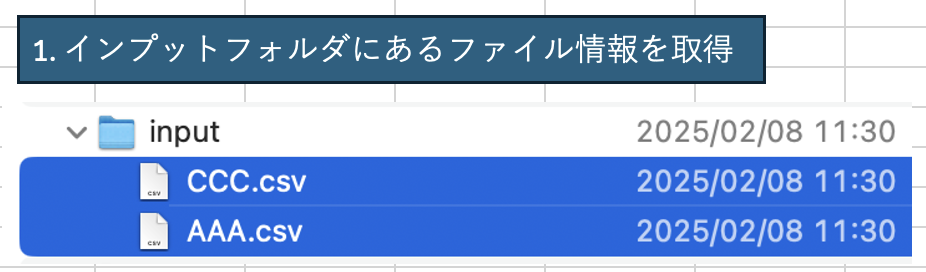
inputフォルダに2つのファイルを格納している。

sqliteにfile_historyテーブルを作成している。そして、2つのファイルを格納している。
処理対象ファイル
処理対象ファイルは、DB格納ファイルよりも新しいファイル。
DB格納されていないファイルは、DBにあると仮定して、その最終更新日時を最も古い値にする。
処理の流れ
- インプットフォルダにあるファイル情報を取得
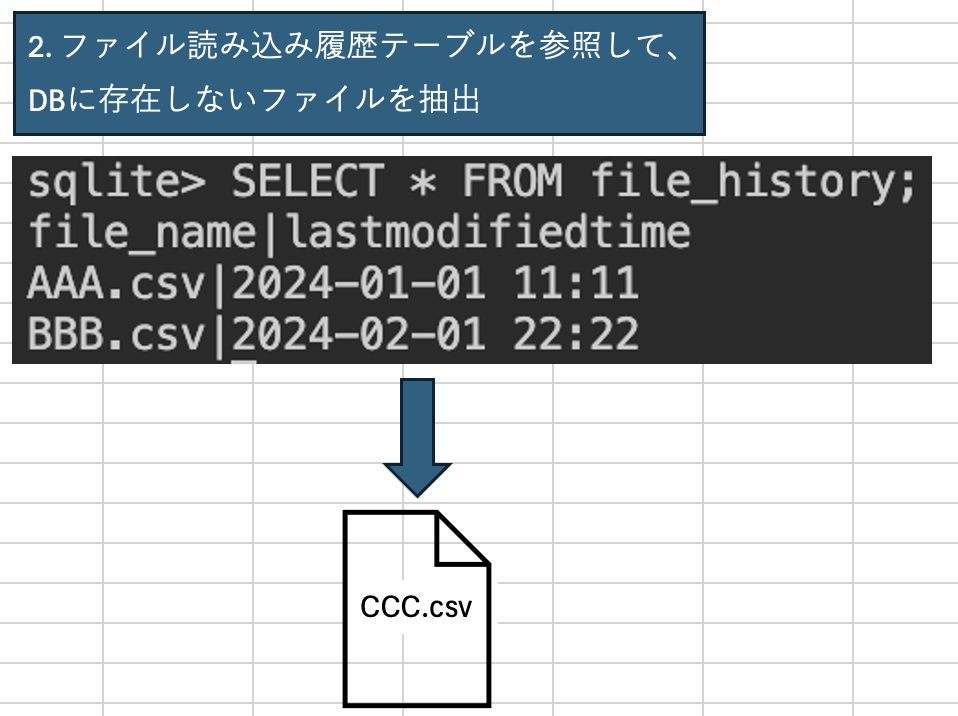
- ファイル読み込み履歴テーブルを参照して、DBに存在しないファイルを抽出
- DBに存在しないファイルの最終更新日時を最も古い日付にする
- インプットフォルダにあるファイルとDBのファイルを最終更新日時で比較して処理対象ファイルを決定
1. インプットフォルダにあるファイル情報を取得
まずは、pandas、sqlite、osモジュール、timedelta関数(標準時からの時差を調整するため)を読み込む。
import pandas as pd
import sqlite3
import os
from datetime import timedelta次に、データベースに接続する。
db_path = "file_history.db"
conn = sqlite3.connect(db_path)
cursor = conn.cursor()続いて、inputフォルダ内のCSVファイルのリストを作成する。リスト内包表記で、inputフォルダにあるファイルリストから、.csvで終わるファイルのみを抽出してリスト化している。
input_folder = "input"
csv_files = [f for f in os.listdir(input_folder) if f.endswith(".csv")]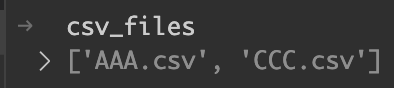
そして、ファイル情報を格納するためのリストfile_dataを定義する。現状は空である。for文で、csv_filesの要素をfile_nameとして一つ一つ取り出して処理を行う。
file_data = []
for file_name in csv_files:for文の中身を見ていこう。まずは、file_pathにファイルのパスを格納している。そして、最終更新日時をlast_modifiedに代入している。os.path.getmtimeメソッドにfile_pathを渡すことで最終更新日時が得られる。
file_path = os.path.join(input_folder, file_name)
last_modified = os.path.getmtime(file_path) # 最終更新日時last_modifiedは、1970年1月1日 00:00:00 UTCを基準とした経過秒数として記録されている。last_modified_timeには、pandasのto_datetimeを使用して日時型に変換されたlast_modifiedが代入されている。unit=”s”を指定することで、数値が秒として解釈される。timedelta関数で、標準時からの9時間の時差を追加して、日本時間にしている。DBとの差異をなくすために、floor関数で秒単位で丸めるということも行なっている。
last_modified_time = pd.to_datetime(last_modified, unit="s") + timedelta(hours=9) # 変換
last_modified_time = last_modified_time.floor('S') # 秒単位で丸めるfor文が始まる前に定義したfile_dataには、辞書形式でファイル名とタイムスタンプの情報を追加する。ファイルの数だけ辞書が1セット追加される。
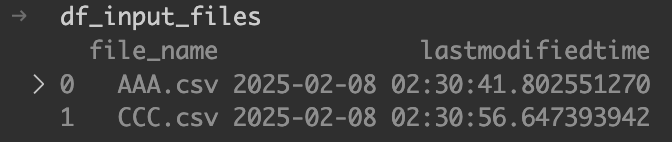
file_data.append({"file_name": file_name, "lastmodifiedtime": last_modified_time})後続の処理で使用するために、pandasのデータフレーム形式にする。
df_input_files = pd.DataFrame(file_data)これで、インプットフォルダにあるCSVファイルの情報が取得できた。
2. ファイル読み込み履歴テーブルを参照して、DBに存在しないファイルを抽出
DBに存在するファイルを特定する
まずは、2つのリストを作成する。db_filesは、DB登録済みファイル名を格納するために作成する。file_data_dbには、タイムスタンプも追加した情報を格納する。
db_files = []
file_data_db = []for文で、inputフォルダにあるcsvファイル一つ一つに対して処理を行っていく。
for file_name in csv_files:WHERE句の条件にinputフォルダのファイル名を渡している。SQLインジェクションを防ぐために、SQL文に値を直接渡さずに、executeメソッドの第二引数にパラメータとして渡したものを使用している。
query = "SELECT file_name, lastmodifiedtime FROM file_history WHERE file_name = :FILE_NAME"
cursor.execute(query, {"FILE_NAME": file_name})fetchoneメソッドでクエリの結果から一行取得している。インプットファイルと一致するファイル名は一つしかないはずなので、これでOK。
result = cursor.fetchone()結果があった場合、db_filesとfile_data_dbに値を挿入する。resultはタプルなので、インデックス番号を[]の中に書くことで、値を取得できる。
if result:
db_files.append(result[0]) # 取得したファイル名のみリストに追加
file_data_db.append({"file_name": result[0], "lastmodifiedtime": result[1]})最後に、file_data_dbをデータフレーム化したものを「df_db_exists_file」という変数に代入する。
df_db_exists_file = pd.DataFrame(file_data_db)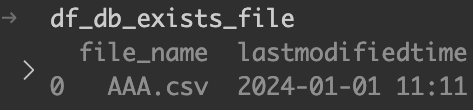
DBに存在しているファイルが特定された。
DBに存在しないファイルを抽出する
次に、ファイル履歴テーブルに存在しないファイルを抽出する。最終的には、df_new_filesに代入されるのだが、いろんな処理を行っているので、一つ一つ見ていこう。
df_new_files = df_input_files[~df_input_files["file_name"].isin(df_db_exists_file["file_name"])].copy()DBに存在するファイル名と、inputフォルダにあるファイル名を比較する。そのために、それぞれのデータフレームとfile_nameカラムを使用している。
df_new_files = df_input_files[~df_input_files["file_name"].isin(df_db_exists_file["file_name"])].copy()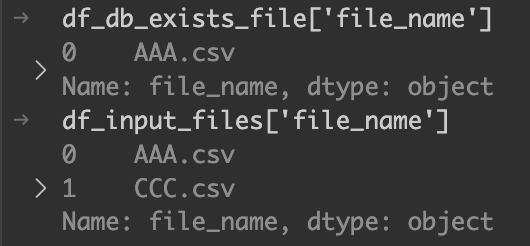
isinメソッドで、ファイル名がDBにあるかどうかを判定している。インデックス0のAAA.csvはDBに存在するので、Trueになる。
df_new_files = df_input_files[~df_input_files["file_name"].isin(df_db_exists_file["file_name"])].copy()
今回、DBに存在しないファイルを抽出したいので、上記の真偽値を反転させる。
df_new_files = df_input_files[~df_input_files["file_name"].isin(df_db_exists_file["file_name"])].copy()
こちらをフィルター条件に使用する。
df_new_files = df_input_files[~df_input_files["file_name"].isin(df_db_exists_file["file_name"])].copy()
ファイル履歴テーブルに存在しないファイルを抽出することができた。
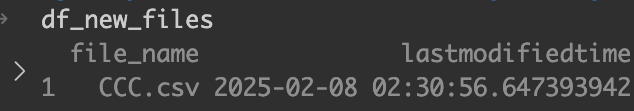
3. DBに存在しないファイルの最終更新日時を最も古い日付にする
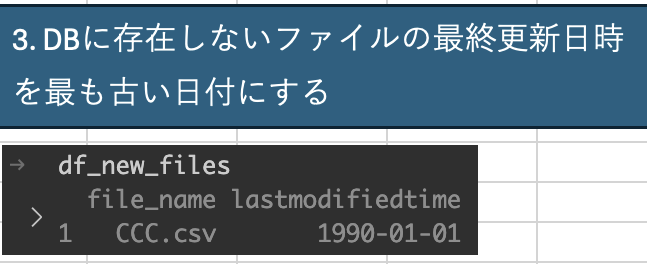
後続の処理で、最終更新日時がDBよりも新しいファイルを処理対象ファイルとしている。
DBに存在しないファイルは、処理対象ファイルとしたい。
そのため、最終更新日時をDBと比較したときに、必ず新しくなるように、一番古い日付に変更する。
oldest_time = pd.Timestamp("1990-01-01 00:00:00")
df_new_files["lastmodifiedtime"] = oldest_time # 一番古い日付に設定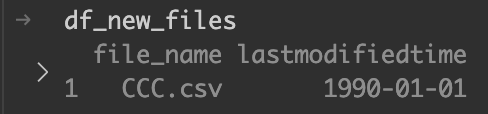
4. インプットフォルダにあるファイルとDBのファイルを最終更新日時で比較して処理対象ファイルを決定
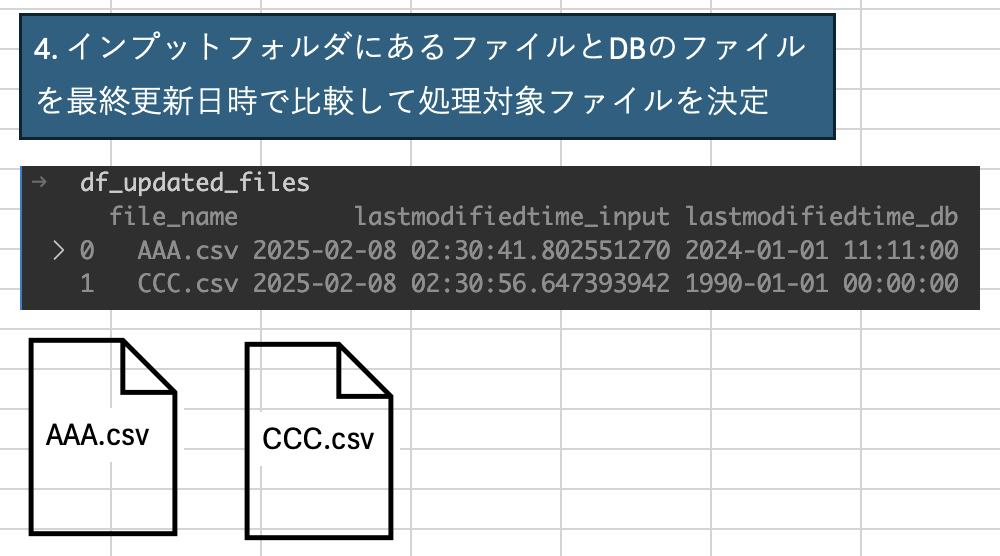
まずは、concatメソッドを使用して、DBに存在していたファイルとDBに存在していなかったファイルのデータフレームを縦に結合する。
df_history_result_files = pd.concat([df_db_exists_file, df_new_files], ignore_index=True) # DBファイル + 1990年設定の新規ファイルDBに存在していたファイルとDBに存在していなかったファイルのデータフレームはこちら。
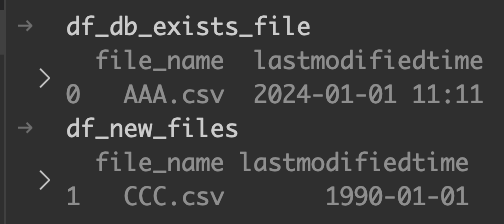
2つのデータフレームが縦に結合された。ファイル履歴テーブルを参照した結果のファイルということで、df_history_result_filesという変数名にした。
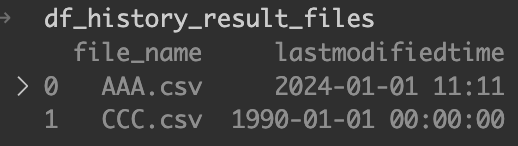
続いて、最終更新日時で比較するために、インプットファイルのデータフレームと、ファイル履歴テーブルを参照した結果のデータフレームを横に結合する。
df_merged_files = df_input_files.merge(df_history_result_files, on="file_name", suffixes=("_input", "_db"))結合条件は、file_name。
df_merged_files = df_input_files.merge(df_history_result_files, on="file_name", suffixes=("_input", "_db"))suffixesを「suffixes=(“_input”, “_db”)」と指定することで、基準となるインプットファイルのデータフレームのカラム名の後ろには「_input」、結合されるファイル履歴テーブルのデータフレームのカラム名の後ろには「_db」が付与される。
df_merged_files = df_input_files.merge(df_history_result_files, on="file_name", suffixes=("_input", "_db"))
二つの最終更新日時を比較する前の処理を行う。
現状は以下のように、DB側が日時型ではないので、型を揃える必要がある。
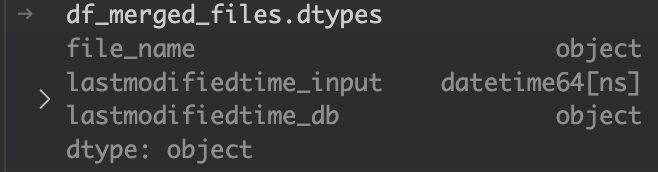
pandasのto_datetime関数を使用して、DB側を日時型に変換する。
df_merged_files["lastmodifiedtime_db"] = pd.to_datetime(df_merged_files["lastmodifiedtime_db"])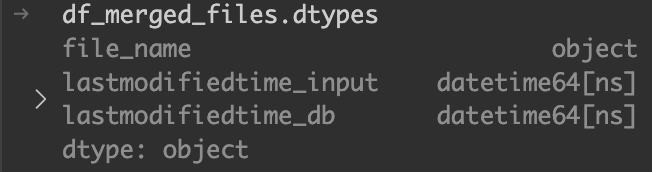
最後に、最終更新日時がDBよりも新しいファイルのみにフィルタリングしている。
df_updated_files = df_merged_files[df_merged_files["lastmodifiedtime_input"] > df_merged_files["lastmodifiedtime_db"]]といっても、見た目に変化はない。

動作確認条件と期待結果
以下の条件で処理対象ファイルのフィルタリングが上手くいっているか確かめてみよう。
| 格納場所 | ファイル名 | 最終更新日時 |
| インプット | AAA.csv | 2025-02-08 11:30 |
| インプット | BBB.csv | 今日(2025-02-15) 15:11 |
| インプット | CCC.csv | 今日(2025-02-15) 15:07 |
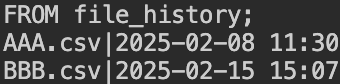
| ファイル履歴テーブル | AAA.csv | 2025-02-08 11:30 |
| ファイル履歴テーブル | BBB.csv | 2025-02-15 15:07 |
インプットはこちら。

ファイル履歴テーブルはこちら。
ファイル名と期待結果を以下にまとめた。
| ファイル名 | 期待結果 | 理由 |
| AAA.csv | 処理対象ファイルに含まれない | DBにあって、最終更新日時が新しくないから |
| BBB.csv | 処理対象ファイルに含まれる | DBにあるが、最終更新日時が新しいから |
| CCC.csv | 処理対象ファイルに含まれる | DBにないから |
動作確認結果
# 📌 9. 結果の表示
print("🔹 更新が必要なファイル (新規ファイルも含む):")
df_updated_files = df_updated_files.sort_values('file_name').reset_index(drop=True)
print(df_updated_files)
# 📌 10. データベース接続を閉じる
conn.close()
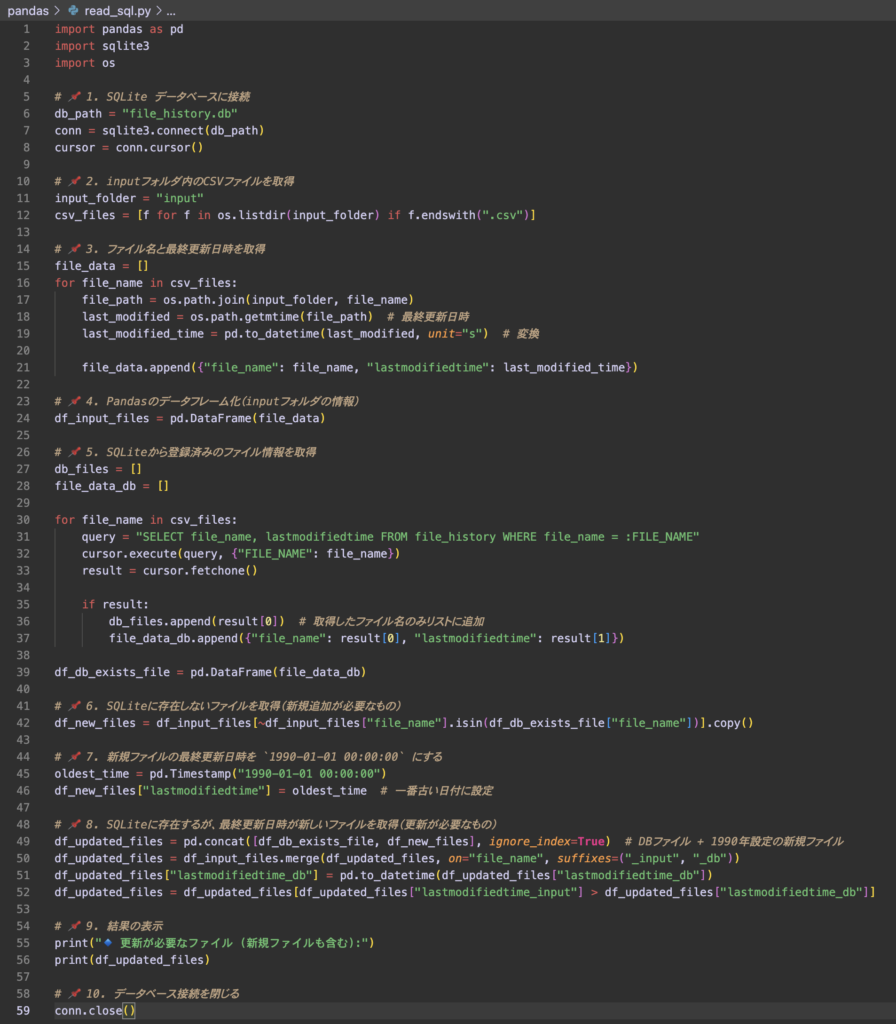
全ソースコード
import pandas as pd
import sqlite3
import os
from datetime import timedelta
# 📌 1. SQLite データベースに接続
db_path = "file_history.db"
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# 📌 2. inputフォルダ内のCSVファイルを取得
input_folder = "input"
csv_files = [f for f in os.listdir(input_folder) if f.endswith(".csv")]
# 📌 3. ファイル名と最終更新日時を取得
file_data = []
for file_name in csv_files:
file_path = os.path.join(input_folder, file_name)
last_modified = os.path.getmtime(file_path) # 最終更新日時
last_modified_time = pd.to_datetime(last_modified, unit="s") + timedelta(hours=9)
last_modified_time = last_modified_time.floor('S') # 秒単位で丸める
file_data.append({"file_name": file_name, "lastmodifiedtime": last_modified_time})
# 📌 4. Pandasのデータフレーム化(inputフォルダの情報)
df_input_files = pd.DataFrame(file_data)
# 📌 5. SQLiteから登録済みのファイル情報を取得
db_files = []
file_data_db = []
for file_name in csv_files:
query = "SELECT file_name, lastmodifiedtime FROM file_history WHERE file_name = :FILE_NAME"
cursor.execute(query, {"FILE_NAME": file_name})
result = cursor.fetchone()
if result:
db_files.append(result[0]) # 取得したファイル名のみリストに追加
file_data_db.append({"file_name": result[0], "lastmodifiedtime": result[1]})
df_db_exists_file = pd.DataFrame(file_data_db)
# 📌 6. SQLiteに存在しないファイルを取得(新規追加が必要なもの)
df_new_files = df_input_files[~df_input_files["file_name"].isin(df_db_exists_file["file_name"])].copy()
# 📌 7. 新規ファイルの最終更新日時を `1990-01-01 00:00:00` にする
oldest_time = pd.Timestamp("1990-01-01 00:00:00")
df_new_files["lastmodifiedtime"] = oldest_time # 一番古い日付に設定
# 📌 8. SQLiteに存在するが、最終更新日時が新しいファイルを取得(更新が必要なもの)
df_history_result_files = pd.concat([df_db_exists_file, df_new_files], ignore_index=True) # DBファイル + 1990年設定の新規ファイル
df_merged_files = df_input_files.merge(df_history_result_files, on="file_name", suffixes=("_input", "_db"))
df_merged_files["lastmodifiedtime_db"] = pd.to_datetime(df_merged_files["lastmodifiedtime_db"])
df_updated_files = df_merged_files[df_merged_files["lastmodifiedtime_input"] > df_merged_files["lastmodifiedtime_db"]]
# 📌 9. 結果の表示
print("🔹 更新が必要なファイル (新規ファイルも含む):")
df_updated_files = df_updated_files.sort_values('file_name').reset_index(drop=True)
print(df_updated_files)
# 📌 10. データベース接続を閉じる
conn.close()
このpandasのスキルを武器にしてキャリアを切り開いていきましょう