2025.09.13(更新日: 2025.09.13)
SQLiteでテーブルを作成して、データを挿入する
はじめに
以下のブログ記事を読んでいて、SQLiteでfile_historyテーブルを作成する方法を忘れてしまっていたことに気づいた。
記録する情報の設計
CREATE TABLE file_history (
id INTEGER PRIMARY KEY AUTOINCREMENT, -- 一意のID
file_name TEXT NOT NULL, -- ファイル名
last_modified TIMESTAMP NOT NULL, -- ファイルの最終更新日時
loaded_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 読み込み日時(デフォルトは現在時刻)
status TEXT -- ステータス(成功/失敗など)
);SQLiteコマンドラインを使って、file_historyテーブルを作成する
ターミナルでSQLiteを起動して、CREATE文を入力する。
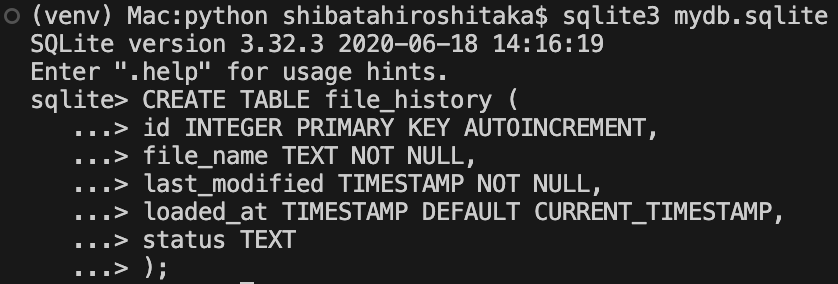
.tablesで作成したテーブルを確認できる。
今自分がいるpythonディレクトリにmydb.sqliteが作成された。
pandas-sql/inputのcsvファイルをfile_historyテーブルに挿入する
とりあえず、sqliteの対話モードは抜ける。

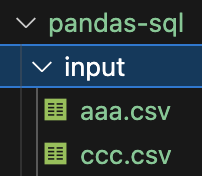
pandas-sql/inputのcsvファイル
以下のpythonを実行するとsqlite3.OperationalError: no such table: main file_historyが発生した。
import os
import glob
import sqlite3
from datetime import datetime, timezone
DB_PATH = "../mydb.sqlite" # 既存DB。パスが別ならここをフルパスに
INPUT_DIR = "/input" # CSVが入っているディレクトリ
# 1) DB接続
conn = sqlite3.connect(DB_PATH)
cur = conn.cursor()
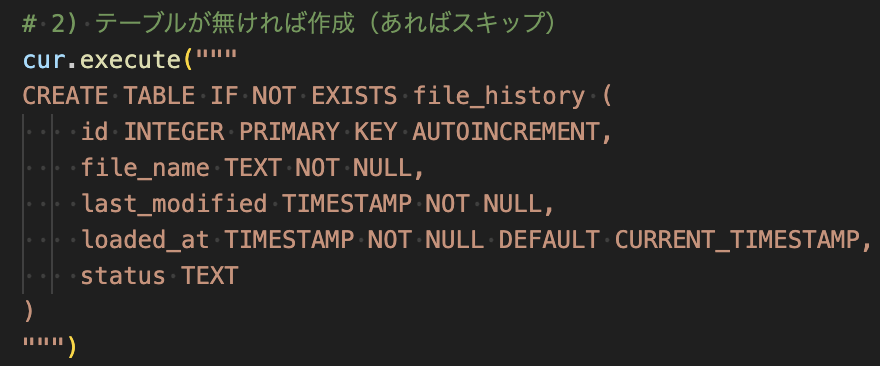
# 2) テーブルが無ければ作成(あればスキップ)
# cur.execute("""
# CREATE TABLE IF NOT EXISTS file_history (
# id INTEGER PRIMARY KEY AUTOINCREMENT,
# file_name TEXT NOT NULL,
# last_modified TIMESTAMP NOT NULL,
# loaded_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
# status TEXT
# )
# """)
# 3) file_name の一意性を確保(無ければ作成)
cur.execute("""
CREATE UNIQUE INDEX IF NOT EXISTS ux_file_history_file_name
ON file_history(file_name)
""")
conn.commit()
# 4) 取り込み対象CSVを列挙
csv_paths = sorted(glob.glob(os.path.join(INPUT_DIR, "*.csv")))
# 5) 1CSV = 1レコードとして履歴にUPSERT
upsert_sql = """
INSERT INTO file_history (file_name, last_modified, loaded_at, status)
VALUES (?, ?, CURRENT_TIMESTAMP, ?)
ON CONFLICT(file_name) DO UPDATE SET
last_modified = excluded.last_modified,
loaded_at = CURRENT_TIMESTAMP,
status = excluded.status
"""
def to_iso_utc(ts):
# ts: epoch秒 → ISO8601(UTC) "YYYY-MM-DD HH:MM:SS"
return datetime.fromtimestamp(ts, tz=timezone.utc).strftime("%Y-%m-%d %H:%M:%S")
inserted = 0
for p in csv_paths:
fname = os.path.basename(p)
mtime = os.path.getmtime(p) # ファイルの最終更新(Epoch秒)
last_modified_iso = to_iso_utc(mtime) # SQLiteに入れやすい文字列に
status = "pending" # 例: まだ本処理前なら pending, 完了時は success
cur.execute(upsert_sql, (fname, last_modified_iso, status))
inserted += 1
conn.commit()
# 6) 結果確認(最新5件)
cur.execute("SELECT id, file_name, last_modified, loaded_at, status FROM file_history ORDER BY loaded_at DESC LIMIT 5")
rows = cur.fetchall()
conn.close()
print(f"Upserted {inserted} rows.")
for r in rows:
print(r)Traceback (most recent call last):
File "/Users/shibatahiroshitaka/Downloads/python/pandas-sql/insert-file-history.py", line 25, in <module>
cur.execute("""
sqlite3.OperationalError: no such table: main.file_historyfile_historyテーブルがあるかどうか確認する。
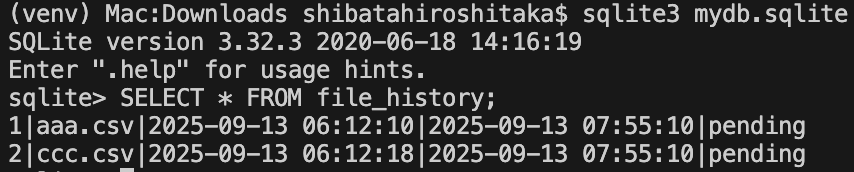
mydb.sqliteに接続して、file_historyテーブルがあるかどうか確認した。

あった。
# 2) テーブルが無ければ作成(あればスキップ)のコメントアウトを外したら、上手く行った。
INPUT_DIRも修正した。

これは、mydb.sqliteから見た時の相対パス。
inputフォルダ内のcsvファイルが、file_historyテーブルに挿入された。

挿入されたデータの確認
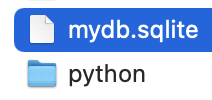
先程作成されたはずのデータは、ソースを実行したpythonディレクトリの一つ上の階層にあるmydb.sqliteに作成されていた。
ソースを実行したpythonディレクトリが基準となって以下の相対パスが解釈されたため。

Downloads > pythonという階層構造になっている。
pythonディレクトリ内にあるmydb.sqliteにデータを挿入する
一つ上の階層にあるmydb.sqliteは削除。
DB_PATHを修正。


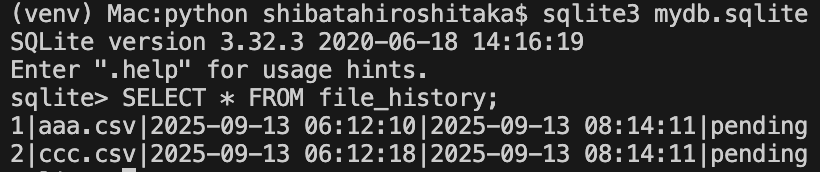
pythonディレクトリに降りる。

ソース実行。

挿入されたデータの確認。
SQLiteを抜ける。

コメントを残す