pythonとExcelでWebスクレイピング Part3
はじめに
前回は「スクレイピングしたい要素を取得する」という部分で戸惑っていた。
全体像は以下となる。
1 必要なライブラリをインポートする
2 WEBサイトにアクセスする
3 スクレイピングしたい要素を取得する ← イマココ
4 取得した内容をExcelのA2〜A4に出力する3回目を進めていこう。
トップページの記事数を変更したので、前回とは記事数に関わる部分で変更がある。
まずやりたいこと
以下のような配列をPythonで作成したい。
[一番上の記事タイトル、二番目の記事タイトル、三番目の記事タイトル]【試行錯誤1】空の配列を作ってみる
pythonでは配列ではなくリストと呼ぶみたいだ。
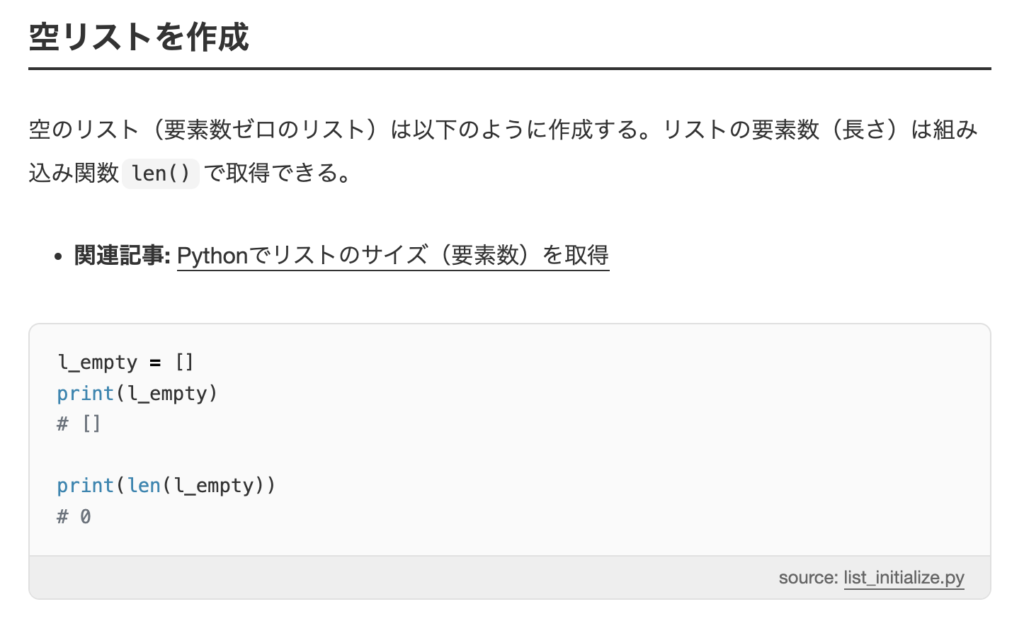
以下のようなリストを作成した。

【試行錯誤2】次はFor文
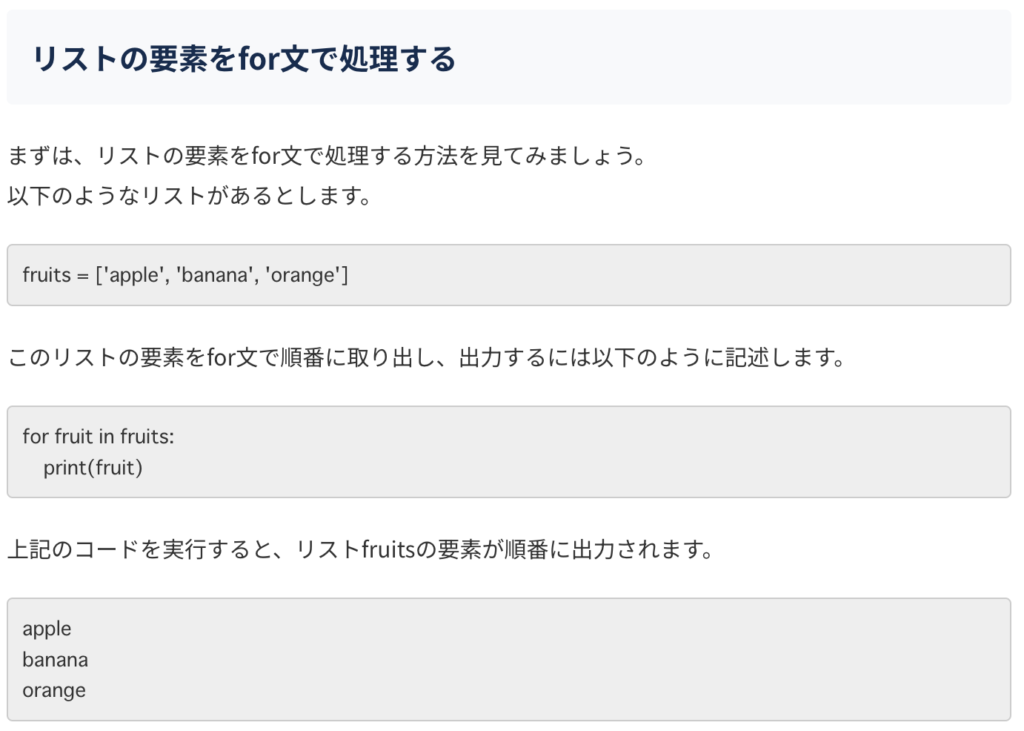
いや、これはリストにすでに入っている要素を一つ一つ出力する処理だ。
空のリストに要素を一つずつ入れていきたい。
【試行錯誤3】Pythonで空のリストに要素を一つずつ入れるには、appendを使う
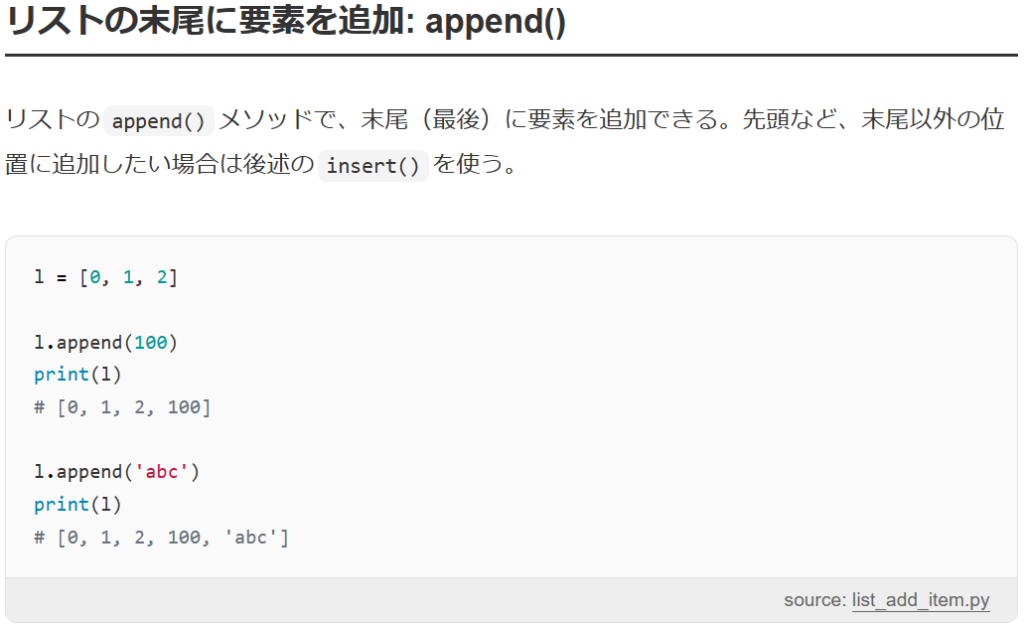
空の配列に記事タイトルを一つずつappendしていくのがいいだろう。
bodyの中身を出力することができた
当サイトのトップページの3記事のタイトルを取得しよう。
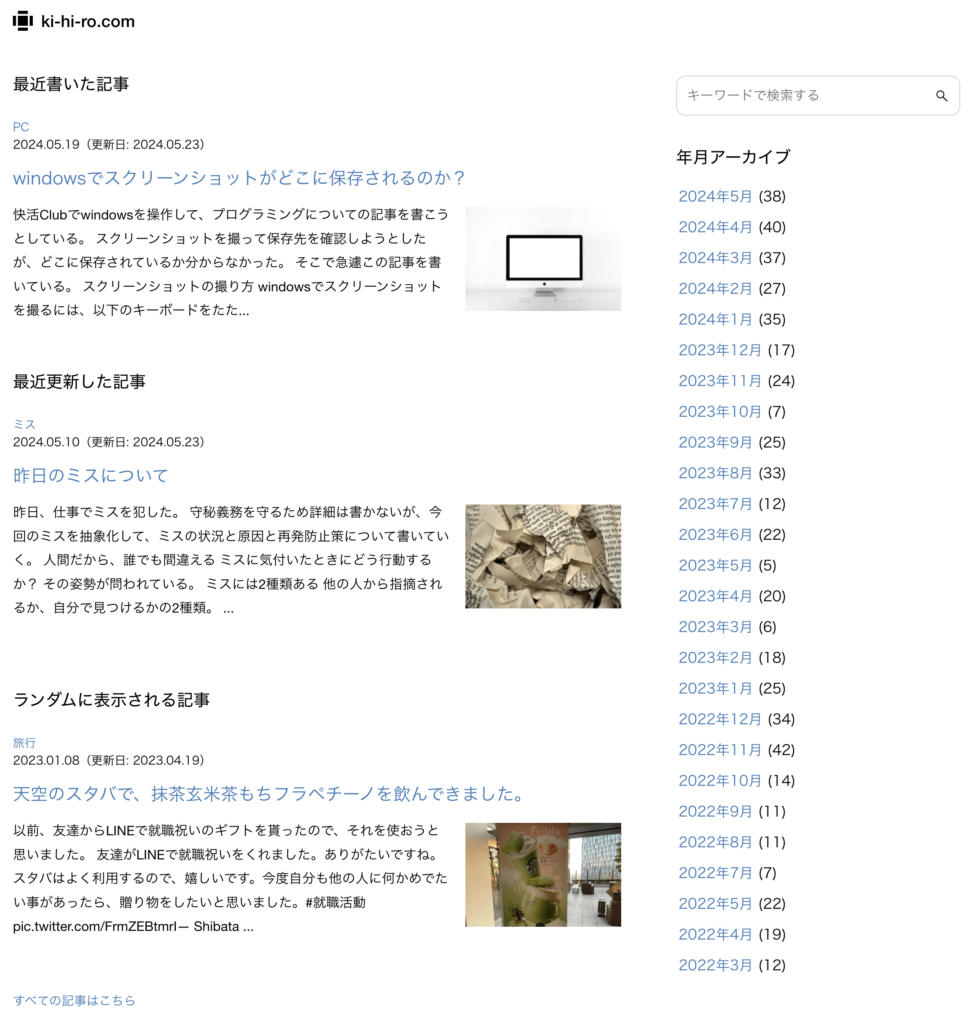
一番大きな要素には、front-pageというクラス名があるので、それを変数に入れる。
select_oneを使用する。(select_oneメソッド)
先ほどクラス名を変数に入れると書いたが、それは間違っていた。
CSSセレクタを指定する必要がある。
idは指定していないので、CSSセレクタはbodyタグのbodyだった。

これを実行すると、大きな括りであるbodyの中身が表示された。
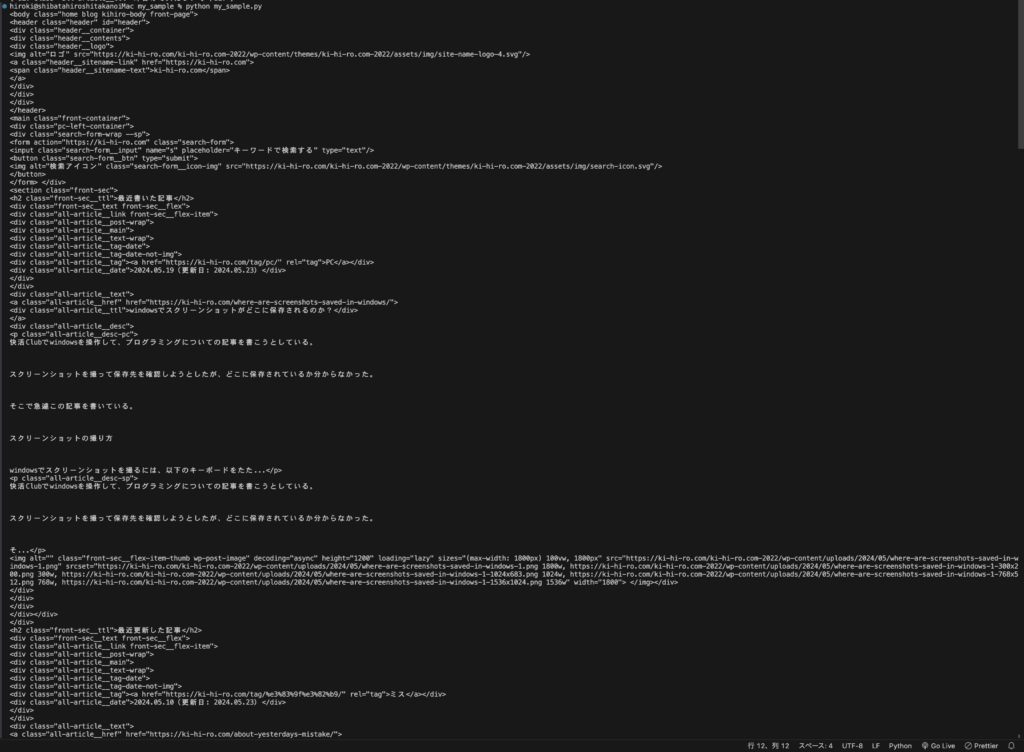
ここから記事タイトルを絞り込んでいく。
全ての記事タイトルをターミナルに出力することに成功した
記事タイトルのCSSセレクタは、div.all-article__ttl。
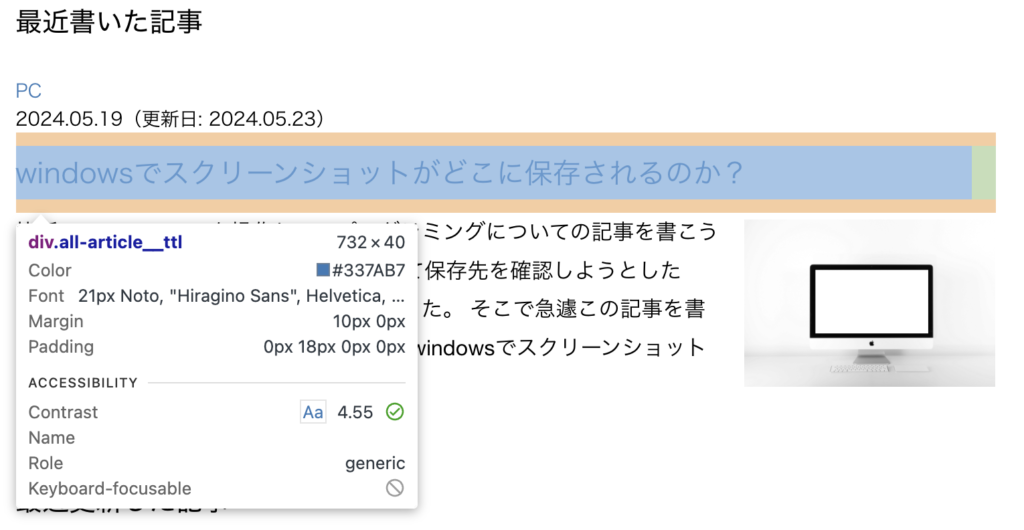
それを、ttlに格納した。

実行すると、全ての記事タイトルのdiv要素が入った配列を出力することができた。

ここからタイトルを抜き出そう。
一つの要素に対して、textメソッドを使用したら、テキストを抜き出すことができた。


for文で順番に出力していこう。

3つの記事タイトルのdiv要素が入っている配列の名前は、ttl_listに変更した。
for文でttl_listからttlという名前で一つずつ取り出して、textメソッドで出力した。
bodyは不要だったので、コメントアウトしておいた。
実行結果はこちら。

トップページにある全ての記事タイトルが出力できた。
次回
今回、「3 スクレイピングしたい要素を取得する」を完了させることができた。
1 必要なライブラリをインポートする
2 WEBサイトにアクセスする
3 スクレイピングしたい要素を取得する ← 今回
4 取得した内容をExcelのA2〜A4に出力する次回は、「4 取得した内容をExcelのA2〜A4に出力する」を行っていく。
コメントを残す