2026.05.20(水) / 13:23
RAGを始めてみました
- ID
- 36962
- Published
- 2026-05-20 13:23
- Modified
- 2026-06-06 03:00
- Author
- khiro
- Tags
- プログラミング
RAG(Retrieval-Augmented Generation)は、検索拡張生成という意味
大規模言語モデル(LLM)が解答を生成する前に、社内データやウェブ上の外部ソースから関連情報を検索し、その情報に基づいて精度の高いテキストを出力させる技術
RAGでやりたいこと
自分のブログ記事を検索できるAIを作ってみたい
RAGを知ったきっかけ
京都一人旅を実行した時に、以下の求人を電車内で見かけた(スマホで)
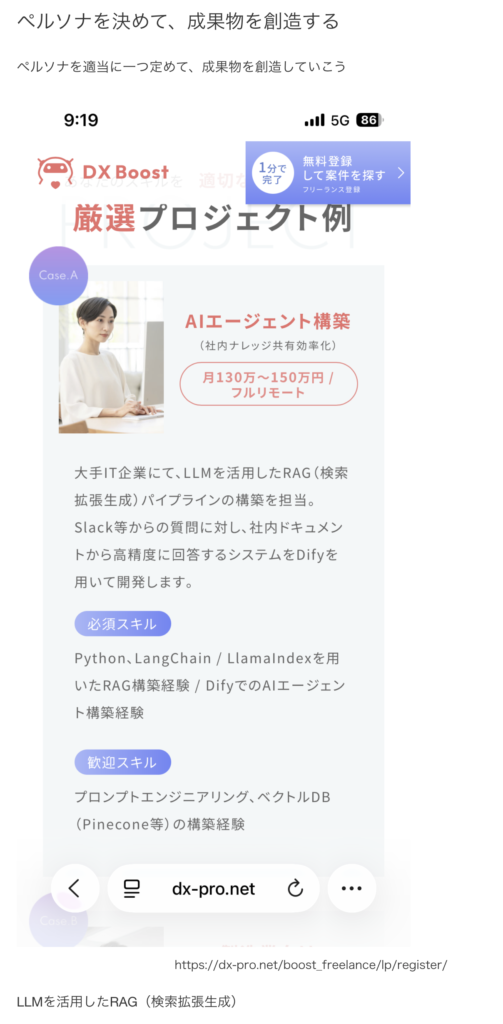
LkamaIndexを用いたRAG構築経験
これで、月130万円のフルリモートに近づくため、夢がある
夢に向かって、走っていこう
RAGの現状
チャッピーと共に進めてきた
ここは大事
RAGはざっくり言うと、
「LLMに、外部知識を検索させてから回答させる仕組み」
です。
ChatGPT単体だと「学習済み知識」でしか答えられませんが、RAGでは、
PDF
Notion
ブログ記事
社内ドキュメント
Markdown
DB
などを検索して、その内容を踏まえて回答できます。最初のおすすめ構成
バックエンド
Python
FastAPI
RAG
LangChain
ChromaDB
LLM
OpenAI API
フロント
Streamlit
または
React
かなり定番構成です。最初に作るならこれがおすすめ
「自分のブログ検索AI」
これ、かなり良い題材です。
理由は、
データを既に持っている
愛着がある
技術ブログ化しやすい
面接で話しやすい
「思想 × 技術」が出る
からです。
流れはこんな感じ。
ステップ
① Markdown or HTMLを読み込む
Pythonで記事取得。
from pathlib import Path
files = Path("./articles").glob("*.md")
② テキストを分割
長文をチャンク化。
from langchain.text_splitter import RecursiveCharacterTextSplitter
③ ベクトル化
文章をembedding化。
from langchain_openai import OpenAIEmbeddings
④ DB保存
from langchain.vectorstores import Chroma
⑤ 質問検索
「Hirokiが自然について書いていた記事を教えて」
みたいな検索。
⑥ LLMへ渡す
検索結果を元に回答生成。詰まっているポイント
app.pyを実行すると、止まる
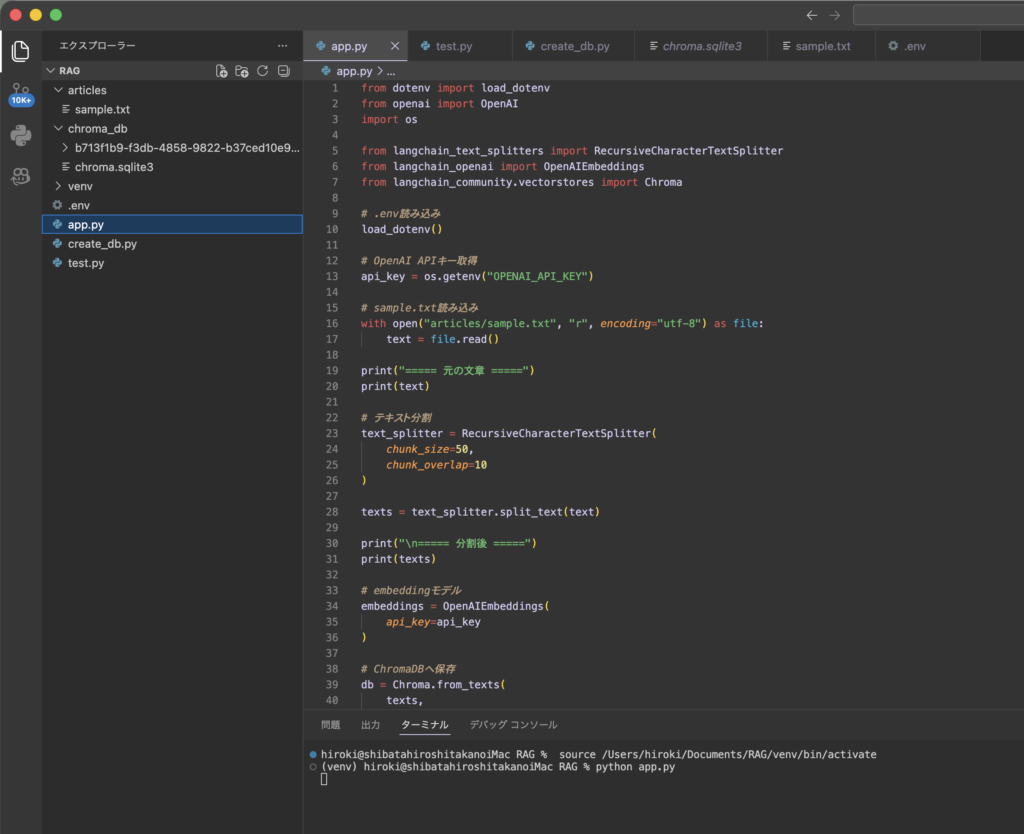
実務でもこういうことは、よくある
これが自分の収入を頭打ちにさせている