pythonとExcelでWebスクレイピング Part2
はじめに
前回、当サイトのトップページにある「最近書いた記事」のタイトルをPythonで引っ張ってくるシリーズのPart1の記事を書いた。
今回は、Part2。
Excelファイルの下準備
以下のようなタイトルを記入した。
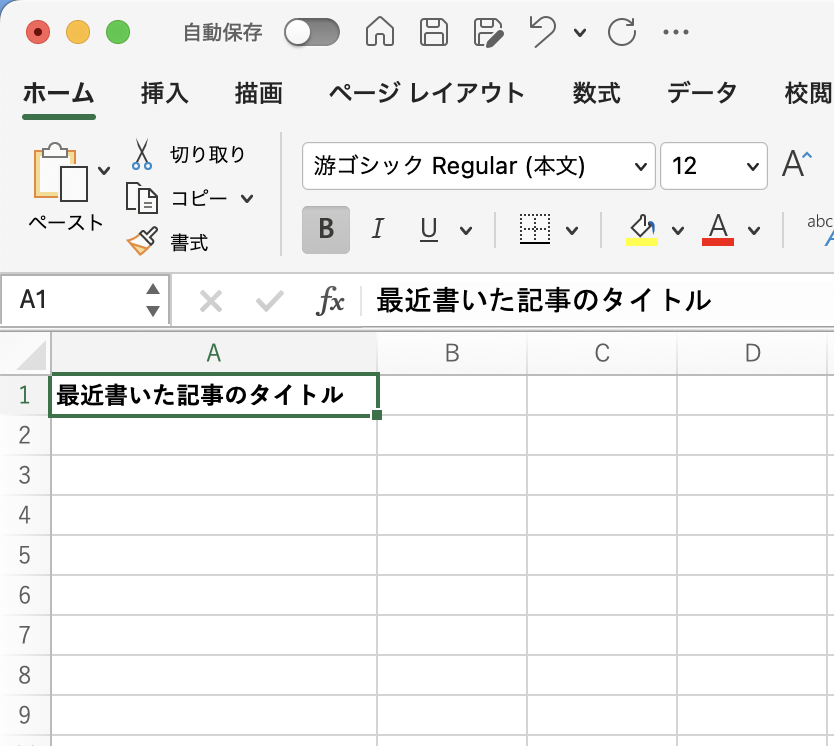
A2以降に記事タイトルをリストアップしていく。
メンタルモデルを作る
以下の参考書の第7章でPythonとExcelでWEBスクレイピングをする内容が書かれているので、その章を理解して、メンタルモデルを作っていく。
プログラムを書いていく
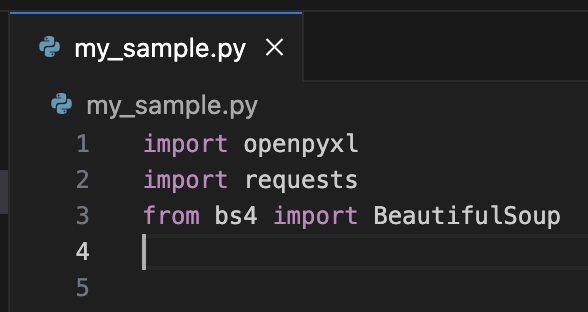
前回までのこちらのソースコードに記述を加えていく。
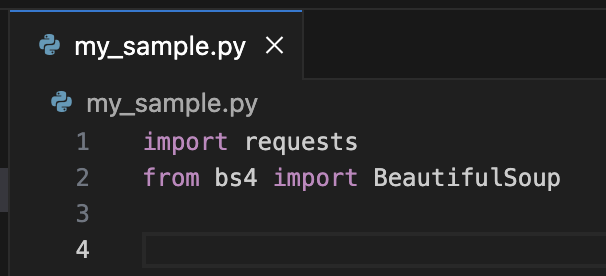
openpyxlもインポートしておこう。

取得したい要素を検証する
当サイトのトップページを開く。
chromeの検証ツールを開き(option + command + I)、矢印を選択する(Shift + command + C)。
記事タイトルには、all-article__ttlというクラス名が付いていることが分かった。
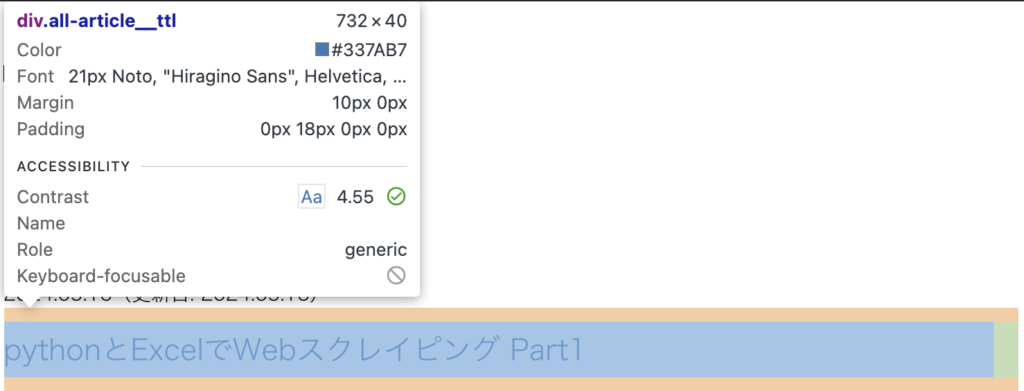
そして、今回取得したい「最近書いた記事」は全部で5件ある。

Excelのアウトプットイメージ
A2〜A6に、最近書いた記事をスクレイピングした結果を表示させたい。

ソースコードの全体像の仮説
どういうコードを書けば、今回やりたいことが実現できるのか?
以下のようなプログラムが考えられる。
1 必要なライブラリをインポートする
2 WEBサイトにアクセスする
3 スクレイピングしたい要素を取得する
4 取得した内容をExcelのA2〜A6に入力する「1 必要なライブラリをインポートする」については、実施済み。
WEBサイトにアクセスする
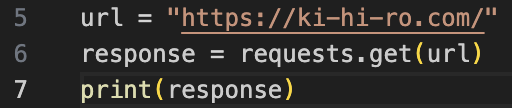
requestsライブラリでアクセスしよう。
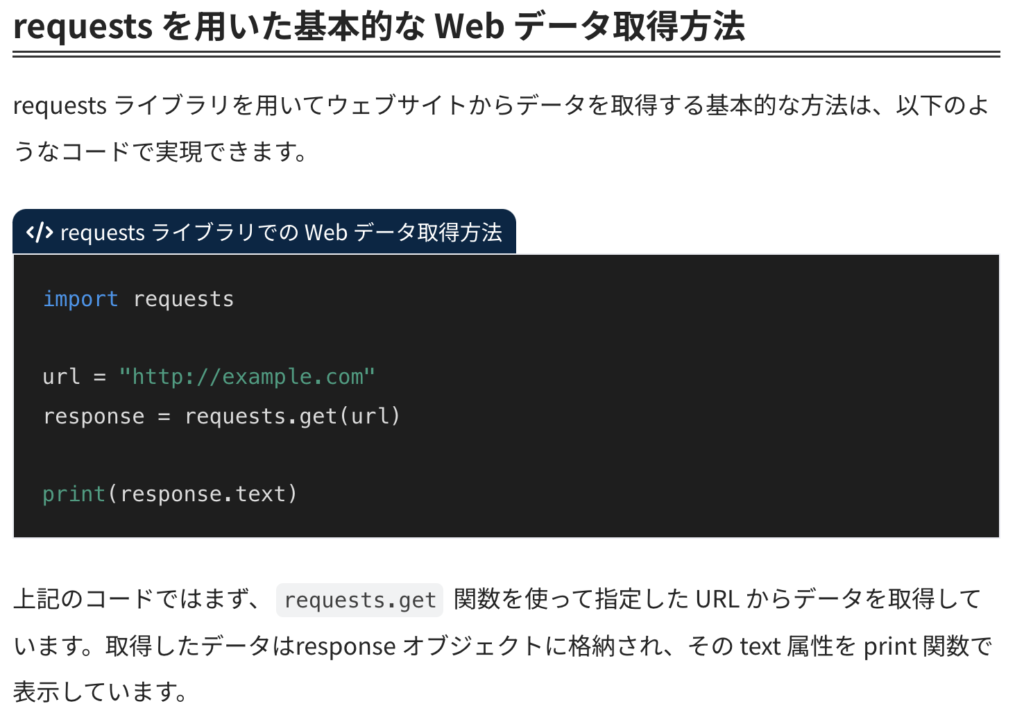
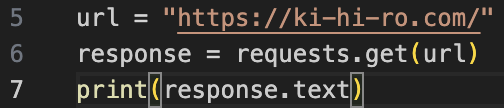
以下のコードを書いてみた。
多すぎて最初の方は省略されていたが、ターミナルで「python my_sample.py(エクセルのファイル名)」を実行すると、以下の出力結果が得られた。
ちなみに、responseの中身は、「Response [200]」というものだった。

スクレイピングしたい要素を取得する
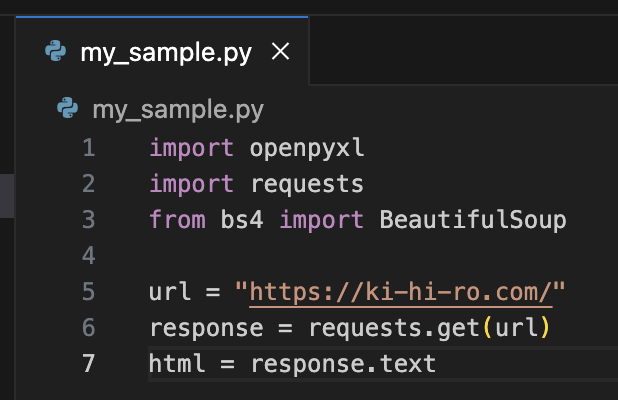
response.textには、HTMLすべてが入っていることが確認できた。
これは、htmlという変数に格納しておこう。
このhtmlから記事タイトルの要素を取得したい。
ここで登場するのが、BeautifulSoup。
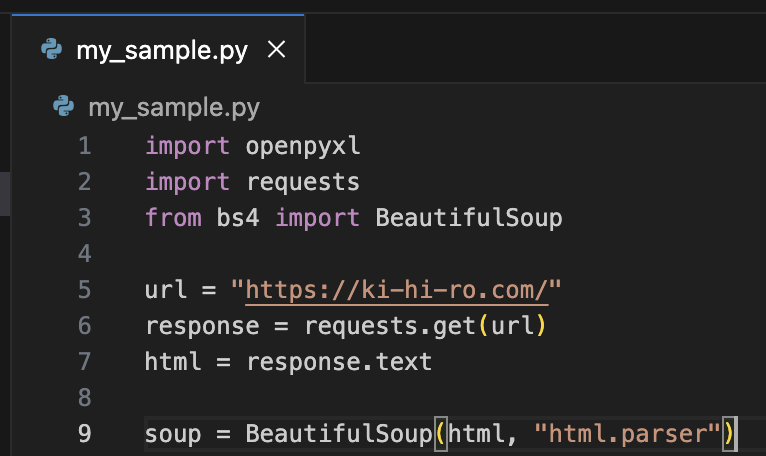
まずは以下のようにして、BeautifulSoupのオブジェクト?を作成する。

今回に当てはめると以下のようになる。
これでHTMLが解析可能になったわけだ。
HTMLという一番大きな括りから、特定の要素を指定するための選択肢は以下の3つ。

今回は、1つ目の方法で行かせてもらう。
CSSセレクタをコピーしよう。
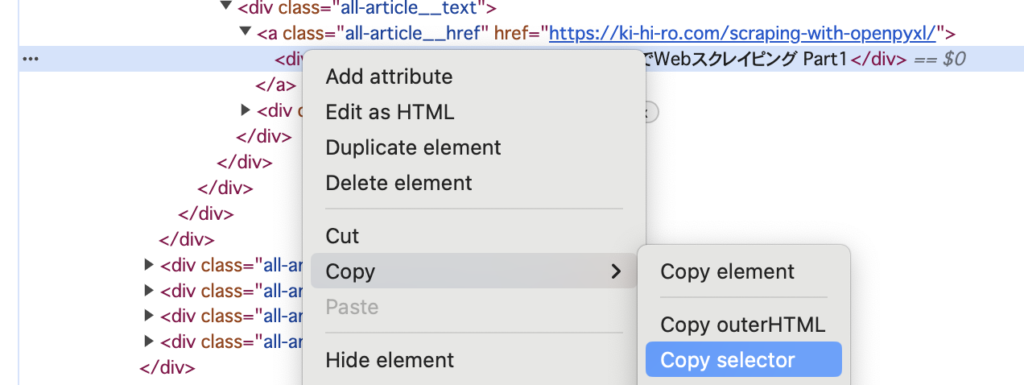
11行目にあるのがCSSセレクタ。
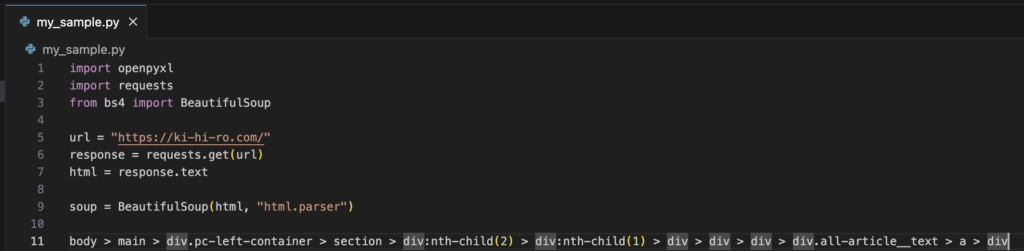
ここで、nth-childはサポートされてないので、nth-of-typeに変換しよう。

変換完了。
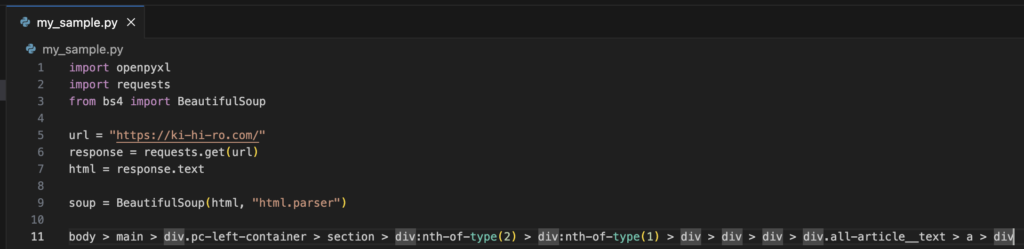
selectメソッドを使用して、表示させようとした。
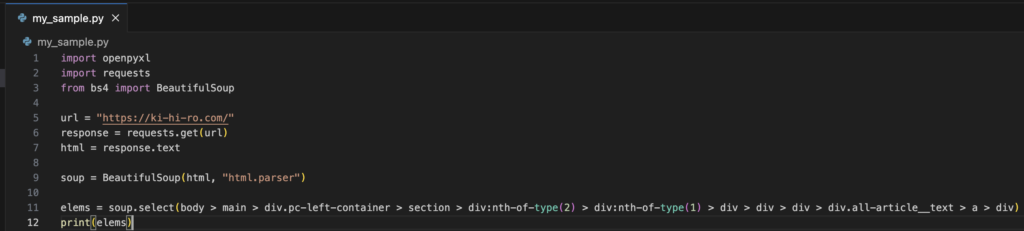
ここで、SyntaxErrorをお目にかかった。

nth-of-typeがダメなのか?
ググるといろいろ出てきた。
もう一度、CSSセレクタのコードを見直す。
body > main > div.pc-left-container > section > div:nth-of-type(2) > div:nth-of-type(1) > div > div > div > div.all-article__text > a > divdivが多い。
多すぎるdivを削除してみた。
body > main > div.pc-left-container > section > div:nth-of-type(2) > div:nth-of-type(1) > div.all-article__text > a 同じ結果だった。

nth-of-typeを削除してみる。

これでどうか?
別のエラー発生(bodyが定義されていない)

ここで重大なミスに気付いた。
参考サイトでは、シングルクオテーションが付いている。

自分の書いたコードでは、シングルクオテーションが付いていなかった。
付けてみたらどうか?

上手く行った。

このように、プログラミングではエラーの直接的な原因ではないエラーメッセージが表示されることがある。
大抵は、それよりも前の記述に問題がある。
前に問題があるから、それ以降のステップに進めないということだ。
上手く行った先ほどの結果は、中身が空だったので、以前のセレクタに戻す。
戻した上で、シングルクオテーションを追加した。

無事、記事タイトルの「ラーメン海鳴」が取得できた。

でもこれだと、最近書いた記事の5件を取得したいという目的から離れている。
おそらく最後の1記事のタイトルが取得されている。
ランダム表示される仕様のため、何回も実行すると、別の記事タイトルが表示される。

ちなみに、elems[0]で最初の要素を取り出すことができた。


といっても一件しかなかった。
理想は以下のような配列が取得できること。
[一番上の記事タイトル、二番目の記事タイトル、三番目の記事タイトル、四番目の記事タイトル、五番目の記事タイトル]一つしか取得できない理由は、CSSセレクタを渡しているからだろう。
最初から5番目までと、一番最後の記事タイトルは、同じCSSセレクタ。
BeautifulSoupがselectメソッドを使用して、上から順番に見て行って、一番下だけを取得している。
いや、最初から最後まで取得した結果の一番最後だけが残っていると考えた方がいい。
なので、繰り返し処理(For文)で、最初から最後までのタイトルを配列に格納して、最初から5件を出力するというアルゴリズムが必要になってくるだろう。
次回(part3)
今回は、以下の全体像の3を試行錯誤しながら進めていった。
1 必要なライブラリをインポートする
2 WEBサイトにアクセスする
3 スクレイピングしたい要素を取得する
4 取得した内容をExcelのA2〜A6に入力する次回は、以下のような配列を試行錯誤して作成するところから始めていきたい。
[一番上の記事タイトル、二番目の記事タイトル、三番目の記事タイトル、四番目の記事タイトル、五番目の記事タイトル]
コメントを残す